

Other Topics — Machine Learning Interview Questions
Introduction
In this article, we will cover the most pertinent aspects of Elastic Net Regression. We will start with discussion on what Elastic Net is in the first place, then move on to a description of how it works and why we would need to use it. Then, we will talk about some of the most important things you need to know to use Elastic Net like a pro! Let’s get into it.
Article Overview
- What is Elastic Net?
- How does Elastic Net work?
- Why is Elastic Net Regression used?
- Elastic Net Regression ML Interview Q&A
What is Elastic Net Regression?
When dealing with linear regression in data science, a common problem one comes across is high dimensionality of the data or over-parameterized models, which can be solved by applying regularization techniques. One of such techniques is the elastic net.
Elastic net is a regression method that is regularized and uses the weighted combination of both L1 and L2 regularization techniques. It does so by addressing the limitations of lasso regression using the combination its (lasso) regularization (L1) and that of ridge regression (L2).
How Does Elastic Net Regression Work?
To understand the inner workings of elastic net regression, one has to first look into lasso and ridge regression as elastic net is based on both of them.

Ridge regression is a way to limit or regularize the number of features, or otherwise called independent variables, in the regression process. It does this regularization by minimizing the coefficients to a very small value by adding a regularization term which is just the product of a constant (often depicted as ) and the sum of the square of the coefficients (coefficients are really the values of the independent variables). Lasso regression almost does the same thing, limiting the number of features or independent variables in the regression except that it doesn’t just minimize the coefficients, it actually eliminates the coefficients completely, so instead of squaring the coefficients like in ridge regression, it just takes the absolute value instead.
The drawback with lasso regression is several, for instance it tends to pick one variable from a group and ignore the others when the group is composed of highly correlated variables. These limitations can be overcome by combining the cost function with the quadratic aspect (i.e. the squared aspect) of the ridge regularization. This combination is what gives birth to the elastic net regression.
Why Elastic Net Regression is Important?
Elastic net regression is considered an important algorithm in the world of data science and that is because of three main reasons;
- As stated earlier, elastic net helps in regularizing high dimensionality by reducing the importance of independent variables that are not significant. This is especially useful in application areas like cancer prognosis, support vector machines, portfolio optimization, metric learning etc.
- Elastic net regression is putting together the best of both worlds of lasso and ridge regression, taking the L1 regularization from lasso regression and L2 regularization from ridge regression. In a way, this makes elastic net regression twice as powerful.
- Elastic net also addresses the limitation of Lasso regression and this is the holy grail of the importance of the elastic net regression.
Elastic Net ML Interview Questions/Answer
The following questions will be quite useful in preparation for a professional interview involving elastic net regression or data science, as well as for gaining a general understanding;
What critique on lasso regression caused the emergence of elastic net regression?
In the original paper for elastic net (Regularization and variable selection via the elastic net, 2005) by Hui Zou and Trevor Hastie, they mentioned 3 main limitations that elastic net sought to address;
- The lasso tends to choose only one variable from a set of variables when the pairwise correlations are all very high. It is also agnostic as to which variable is chosen.
- Because of the nature of the convex optimization problem, the lasso chooses at most n variables before saturating in the p > n situation (p is the number of parameters, n is the sample size). This appears to be a constraint for a variable selection procedure. Furthermore, unless the constraint on the L1-norm of the coefficients is less than a particular value, the lasso is not properly characterized.
- If there are large correlations between predictors in typical n > p circumstances, it has been empirically shown that the lasso’s prediction performance is dominated by ridge regression.
Lasso regression and ridge regression are very similar, what differentiates them from each other?
Although both regression algorithms put a similar constraint on coefficients by introducing a penalty factor, the differentiating factor between them is that lasso completely removes or eliminates the coefficients by reducing them to zero while ridge regressing only minimizes or reduces the coefficients to a very small value. Lasso regression does its work by finding the magnitude of the coefficients while ridge regression just takes the squares instead. Read all about Lasso vs. Ridge regression here.
How were ridge regression and lasso regression combined in elastic net regression despite their differences?
While the loss function for ridge regression was an element in the elastic net regression, it was not the entire loss function that was used. The function shown below is the ridge regularization penalty with the tuning parameter, λ, while that for lasso is shown next.


The penalties for each regression method is highlighted with a box. To form the elastic net regression, the highlighted penalty of Lridge is placed inside the Llasso function as shown below in the elastic net regularization penalty with the tuning parameter, λ1 coming from lasso and λ2 coming from ridge.
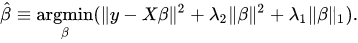
In what cases should elastic net regression be avoided?
If computational cost is an important factor in the application that the regression method is being used for then it is advisable to avoid elastic net regression as it is computationally costly with respect to lasso and ridge regression.
Explain a specific application that would be ideal for elastic net
The regression method would be ideal for cancer prognosis or other medical diagnosis which have tons of independent variables that would need to be sorted according to importance. In this application, compared to other ordinary least squares, elastic net has been proven to show better performance in terms of its prediction accuracy and sparsity.
What is the bias-variance tradeoff?
In statistics, bias may be defined as the difference between the real population and the expected estimated value. Variance, on the other hand, measures the spread, or uncertainty, in these estimates.
As the model complexity increases, the estimates’ variance also increases but then the bias decreases and this is why we regularize using algorithms like lasso, ridge and elastic net: to reduce the variance at the cost of some bias.
What parameters are being tuned in the elastic net algorithm and how do you go about picking the right value for the parameter?
A good method for selecting the right parameter value for λ1 and λ2 is by using cross-validation (CV) especially with ten-fold. Since there are two tuning parameters in elastic net, the cross-validation will have to be done over a 2-dimensional matrix. One would a relatively small range of values for λ2 (0, 0.01, 0.1, 1, 10 ,100) and so for each 2 the algorithm produces the whole solution path of the elastic net. λ1 tuning is also selected by ten-fold CV.
This process can tend to get computationally intensive.
When can the results of the elastic net be the same as that of lasso regression?
Let’s examine the functions for lasso and elastic net regression once more.
If λ2 has a value of zero, which usually happens as a result of overfitting or if a model is too complex, the entire penalty term there will be eliminated and the loss function will be no different than the lasso loss function above it.




