

Other Topics — Machine Learning Interview Questions
Introduction
Not interested in background on Autoencoders? Skip to the questions here.
The field of Artificial Intelligence has Machine Learning as its subset. Machine Learning has Deep Learning as it’s subset. Deep Learning then has algorithms requiring a lot of data to give proper and accurate results. More specifically speaking, algorithms such as neural networks require intensive amounts of data, and if you are talking about images, oftentimes, this data is not available. This is precisely why we need autoencoders. Therefore, let’s discuss them here.
Article Overview
- What are Autoencoders?
- How do Autoencoders Work?
- What are the Uses of Autoencoders?
- Autoencoders ML Interview Questions & Answers
- Wrap Up
What are Autoencoders?
To keep it simple, an autoencoder involves an artificial neural network (ANN) that is an unsupervised machine learning algorithm that applies backpropagation whilst setting the target values equal to the input values. Therefore it is designed in such a way to perform the task of data encoding plus data decoding to reconstruct the actual input.
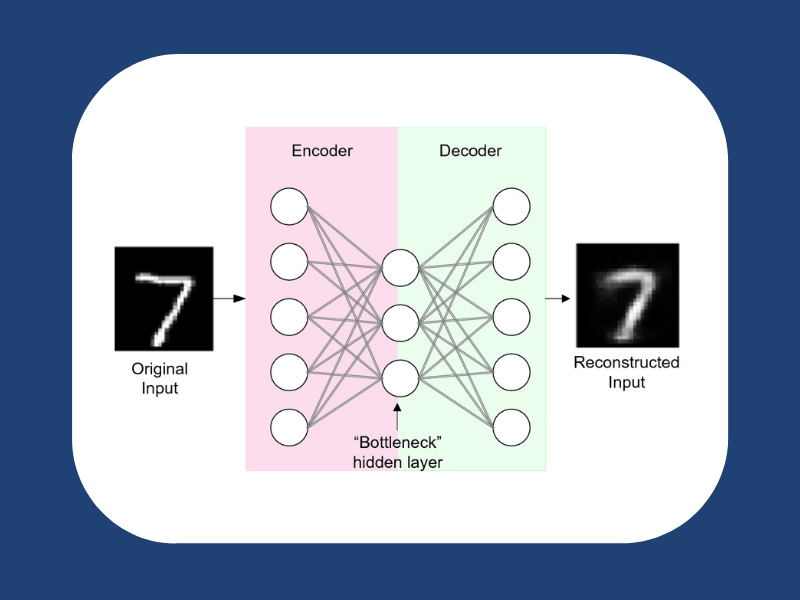
How do Autoencoders Work?
It works using the following components doing the aforementioned tasks:
1) Encoder: The encoder layer encodes the input image into a compressed representation in a reduced dimension. The compressed image is obviously the distorted version of the original image.
2) Code: This part of the network simply represents the compressed input that is fed to the decoder.
3) Decoder: This decoder layer decodes the encoded image back to the original dimension through a lossy reconstruction using the latent space representation.
What are the Uses of Autoencoders?
Autoencoders possess uses that are necessary in the world of images in this day and age. Their uses include the following:
- Dimensionality Reduction
- Image – Denoising
- Feature Extraction
- Data Compression
- Removing Watermarks from Images
Autoencoders ML Interview Questions/Answers
Knowing that there is a methodology to create more data on the pattern of the previous is an absolute joy for ML practitioners working in the world of images. This is exactly why it is only befitting to have a few interview questions related to it. Try to answer them in your head before clicking the arrow to reveal the answer
Two real-life examples of autoencoders’ applications are in:
- Denoising Images: The input seen by the autoencoders is not the raw input but a stochastically corrupted version. Denoising autoencoders are thus trained to reconstruct the original inputs from the noisy versions.
- Image Coloring: In autoencoders, any black and white pictures are converted into colored images. Therefore, depending on what is in the picture, it is possible to tell the color.
- Feature Variation: Here, only required features of an image are extracted and used to generate the output by eradicating noise or unnecessary interruption.
- Dimensionality Reduction: This technique reconstructs our input image but with reduced dimensions. Henceforth, it helps in providing a similar image with a reduced pixel value.
An autoencoder consists of three layers:
- Encoder
- Code
- Decoder
A bottleneck is the layer between the encoder and decoder. It is a well-designed approach to decide which aspects of observed data are relevant and which aspects can be discarded.
It does this by balancing two criteria:
- The compactness of representation is measured as compressibility.
- It retains some behaviorally relevant variables from the input.
Yes, they are as follows:
- Convolutional Autoencoders
- Sparse Autoencoders
- Deep Autoencoders
- Contractive Autoencoders
An autoencoder simultaneously learns an encoding network and decoding network. Therefore when an input (e.g., an image) is given to the encoder, the encoder tries to reduce the input dimensions to a strongly compressed encoded form. This is then fed to the decoder. The neural network learns this encoding/decoding because the loss metric increases with the difference between the input and output image. As a result, the encoder gets a little better at finding an efficient compressed form of the input information after every iteration. The decoder also gets a little better at reconstructing the input from the encoded form.
In Generative Adversarial Networks (GANs), a generator takes some noise signal and transforms it to some target space (for example, with images). On the other hand, the other component (the adversary) is the discriminator, which distinguishes real images that were drawn from the desired target space from amongst the fake images that were created by the generator. Therefore, the network is trained in two alternating phases, each with a different loss.
It differs from PCA (Principal Component Analysis) in the following ways:
- An autoencoder has the ability to learn non-linear transformations with a non-linear activation function and multiple layers.
- They do not need to learn dense layers since it can utilize convolutional layers to learn, which it turns out is better for video, image, and series data.
- It is also more efficient to learn several neural network layers with an autoencoder in comparison to learning one huge transformation with PCA.
- It can incorporate pre-trained layers from another model to apply transfer learning to enhance the encoder/decoder.
Variational autoencoders are generative models, unlike other types of autoencoders. Like GANs, variational autoencoders learn the distribution of the training set, and they are hence widely used in generative tasks.
This constraint is found in the loss function of the sparse encoder is called a sparse constraint. The sparse constraint ensures that the autoencoder is not overfitting the training data when we set the many nodes in the hidden layer.
Wrap Up
To conclude, we see that autoencoders play a pivotal role in the Machine Learning world of today. Their ability to reproduce input data in different forms, specifically from images, makes them extremely useful and even a necessity. They are certainly a hot topic in Deep Learning and deserve all the attention that is given to them!




