

Other Topics — Machine Learning Interview Questions
Introduction
Our problem is that we want a model that does not memorize the training data but learns the actual relationship!
Underfitting is a scenario in data science where a model is unable to capture the relationship between the input and output variables accurately, generating a high error rate on both the training set and unseen data. This is because the model is unable to capture the relationship between the input examples and the target values.
If you are looking for more specific and niche questions to help you ace your Machine Learning Interview, I recommend you check out some of my other topic specific machine learning question lists here
Article Overview
- Is a model that performs poorly on predicting development and production data due to underfitting?
- What are good indicators of an underfitting model?
- What could be a logical prevention strategy for underfitting?
- How can you make a model flexible to decrease the error value?
- Wrap Up
Our model performs poorly in predicting both the development and production data. Is this due to Underfitting? Explain how.
The poor predictive power of a model on development and production data could be because the model is too simple (the input features are not expressive enough) to describe the target well. It could also be because the learning algorithm did not have enough data to learn from.
In this scenario, Underfitting takes place when there is still room for improvement on the training data. This can happen for a number of reasons: If the model is not powerful enough, is over-regularized, or has simply not been trained long enough. This means the network has not learned the relevant patterns in the training data.
How to indicate that your model is underfitting a given dataset?
High bias and low variance are good indicators of Underfitting. Since this behavior can be seen while using the training dataset, underfitted models are usually easier to identify than overfitted ones. Variance refers to how much the model is dependent on the training data. For the case of a 1-degree polynomial, the model depends very little on the training data because it barely pays any attention to the points! Instead, the model has a high bias, which means it makes a strong assumption about the data.
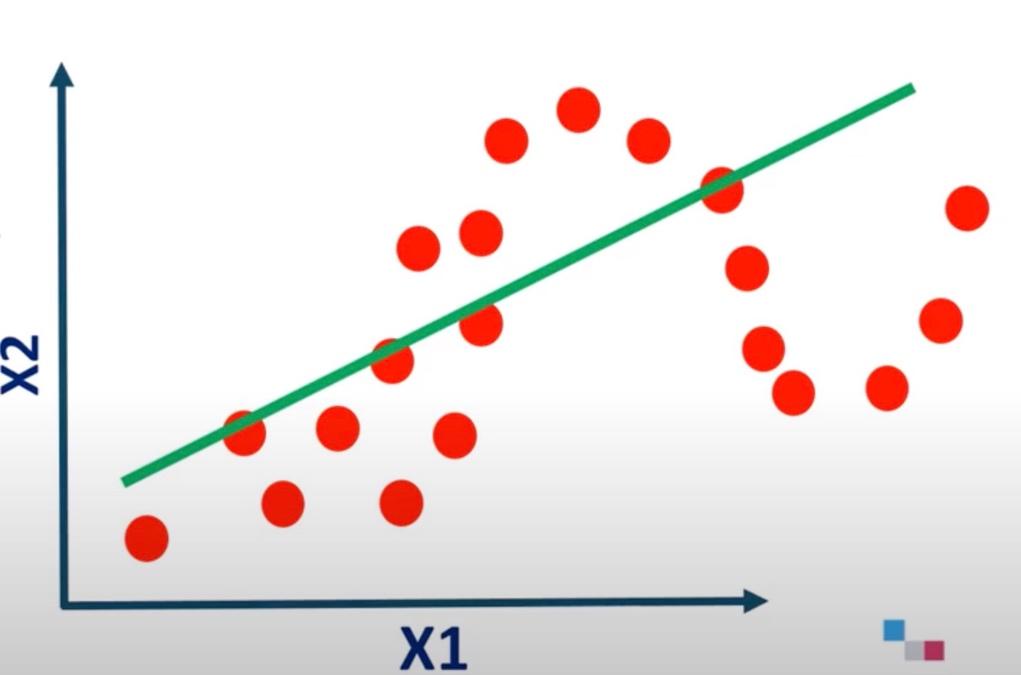
To get a clear picture of Underfitting, let’s assume that we’re trying to obtain the relationship between these two features X1 and X2, and these red dots are coming from the training data. So, this model is basically too straightforward. It’s just a straight line; however my data points are actually non-linear and are too complex for this basic model. This indicates that my model right now is underfitting the training data because this simple model cannot reflect the complexity of the training data set. It is like asking a beginner driver who used to drive cars to go and drive a truck, clearly they will mess up because they are not trained for the complexity; they don’t have the skill set to perform that task.
Similarly, if you have highly non-linear data and try to fit a linear model, you will generally find that you don’t get much accurate results.
What could be a logical prevention strategy for underfitting?
If undertraining or lack of complexity results in Underfitting, then a logical prevention strategy would be to increase the duration of training. Stopping training too soon can also result in underfit model. Therefore, by extending the duration of the training, it can be avoided. However, it is essential to be mindful of overtraining, and subsequently, overfitting. Finding the balance between the two scenarios is the key.
Underfitting can also occur due to rigidity of the model, how can you make a model flexible to decrease the error value?
Performance can also be improved by increasing model flexibility. As the flexibility in the model increases (by increasing the polynomial degree), the training error continually decreases due to increased flexibility. However, the error on the testing set only decreases as we add flexibility up to a certain point. To increase model flexibility, try the following:
Adding Features To Training Data
In contrast to overfitting, your model may be underfitting because the training data is too simple. It may lack the features that will make the model detect the relevant patterns to make accurate predictions. Adding features and complexity to your data can help overcome Underfitting. For example, you might add more hidden neurons in a neural network, or in a random forest, you may add more trees. This process will inject more complexity into the model, yielding better training results. Add new domain-specific features and more feature Cartesian products, and change the types of feature processing used (e.g., increasing n-grams size).
Reducing Regularization
By decreasing the amount of regularization, more complexity and variation is introduced into the model, allowing for successful training of the model. There are a number of different methods, such as L1 regularization, Lasso regularization, dropout, etc., which help reduce the noise and outliers within a model. However, if the data features become too uniform, the model is unable to identify the dominant trend, leading to Underfitting.
Increasing The Model Complexity
Your model may be underfitting simply because it is not complex enough to capture patterns in the data. In this situation, the best strategy is to increase the model complexity by either increasing the number of parameters of your deep learning model or the order of your model. Using a more complex model, for instance, switching from a linear to a non-linear model or adding hidden layers to your neural network, will often help solve Underfitting. If we use a large enough model, it can even achieve a training error of zero, i.e., the model will memorize the data and suffer from over-fitting. The goal is to hit the optimal sweet spot.
Wrap Up
Training a machine learning model involves finding the balance between a model that is underfitted and one that is overfitted, yielding a model that has a good fit. The ideal scenario when fitting a model is identifying that “sweet spot” between Underfitting and overfitting that allows machine learning models to make predictions with accuracy.




