

Other Topics — Machine Learning Interview Questions
Introduction
A key challenge in machine learning is that we cannot tell how well our model will perform on new data until we actually test it. If our model does much better on the training set than on the test set, then we’re likely overfitting. For example, it would be a big red flag if our model saw 99% accuracy on the training set but only 55% accuracy on the test set. This means our model doesn’t generalize well from our training data to unseen data.
If you are looking for more specific and niche questions geared towards Intermediate and Advanced readers, I recommend you check out some of my other topic specific machine learning question lists here
Article Overview
- Is a model that outputs the same label for every class an example of overfitting and why?
- In what ways can you rebalance a dataset?
- What are some other ways to deal with the challenge of overfitting?
Our model is outputting the same label for every class, is this an example of overfitting, and why?
If the model predicts the same output for every class, this means that there is a huge class imbalance in your dataset, which results in the overfitting of the model. Overfitting is when you have a model that tries to adapt itself too much to the data that you have. As a result, the model always predicts the same class for all validation and test examples, and the accuracy is stuck at one point. It can also happen if we don’t shuffle the training set before training the model. This may cause overfitting because the model can only see the data with the same label in the last batch.
In what ways can you rebalance a dataset to even out the classes?
We have a number of approaches to handle an imbalanced dataset; the two most common ones are under-sampling and over-sampling. Under-sampling balances the dataset by reducing the size of the abundant class. This method is used when the quantity of data is sufficient. On the contrary, oversampling is used when the quantity of data is insufficient. It tries to balance the dataset by increasing the size of rare samples.
If you are not able to create a balanced dataset due to lack of data from a particular class, another option is to re-weight the loss function to penalize the majority class. We can adjust class weights by setting a higher class weight for less frequent classes, in this way, we will be promoting the model to give more attention to the downsampled class.
What are some other ways to deal with the challenge of overfitting?
This problem can be resolved using various techniques.
Cross-Validation
One of the best ways that we have found to prevent overfitting is a technique known as k-fold Cross-Validation. The basic approach of this technique is that we divide the data set into two populations, i.e., two sets; one of them is the training population, and the other is the testing population. These subsets are also called “folds.”
Let us see this with an example,
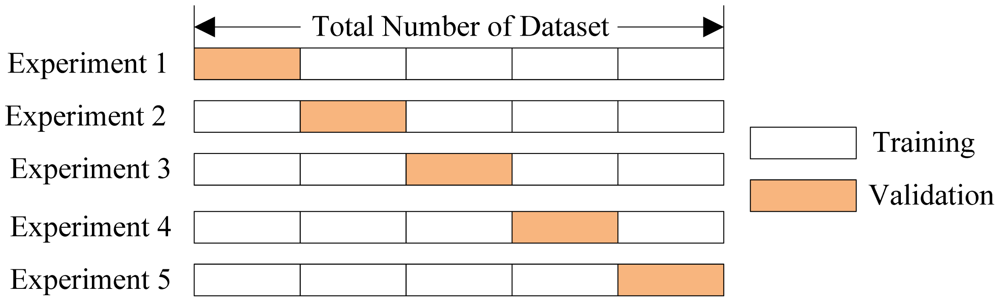
Let’s say this is the experiment we’re trying to perform, and in that experiment, we have some kind of parameters. The data set is split into training population and test population. We create five subsets, and out of those five, we are using four subsets for training, and one is being used for validation. And after validation, we move on to the testing part. This experiment is kept on repeating in different ways with different kinds of parameters. In this way, we minimize the chances of our model memorizing the training data set because now it gets a different kind of training data set every time.
Based on that, if it performs well, then only our model is robust enough to avoid overfitting. In the end, we average the scores for each of the folds to determine the overall performance of a given model. To select the most suitable model, we can create models with a range of different degrees and evaluate each using cross-validation. The model with the lowest cross-validation score will perform best on the testing data and will achieve a balance between underfitting and overfitting.
Get More Training Data
Another way to avoid overfitting is to collect more complete training data. If we collect more data initially, we can be sure that the chances of overfitting are less because our model can learn and memorize the data set very easily with a smaller dataset. The dataset should cover the full range of inputs that the model is expected to handle. But one should ensure to add a clean and relevant dataset; if we just add more noisy data, this technique won’t help.
L1/L2 Regularization
A common way to mitigate overfitting is to put constraints on the complexity of a network by forcing its weights only to take small values, which makes the distribution of weight values more “regular.” Thus, Regularization is a technique to reduce the error by fitting a function appropriately on the given training set and avoiding overfitting. In L1 or L2 regularization, we can add a penalty term on the loss function to push the estimated coefficients towards zero. L2 Regularization shrinks the coefficients for least important predictors to almost zero, without completely removing them, whereas L1 helps in reducing overfitting by removing unnecessary features, the features that are not strong predictors, also known as noise, by pushing the coefficient estimates to be exactly equal to zero. This helps in reducing the variance as well as boosting the performance of a model. Read about it in detail here.
Early Stopping
When you’re training a learning algorithm iteratively, you can measure how well each iteration of the model performs. Up until a certain number of iterations, new iterations improve the model. Once the validation loss stops decreasing but rather begins increasing, we stop the training and save the current model.
Early stopping refers to stopping the training process before the learner passes that point of decline.
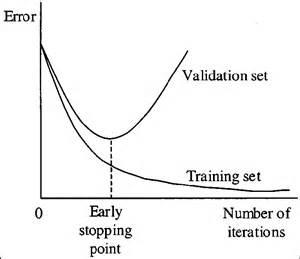
While training the model, we are iterating through different kinds of hyperparameters in the beginning. There is a high bias and low variance scenario, but after some time when the bias reduces, the model starts working very well. After that point, what happens is that the model’s performance starts reducing because of the overfitting on the training data set. That is why we must stop training at the right time. If we stop too early, underfitting may occur, so we have to find the right tradeoff point where we stop and that is the place where we can avoid the overfitting.
This technique is mainly used in deep learning, while other techniques (e.g., Regularization) are preferred for classical machine learning.




