


Other Topics — Machine Learning Interview Questions
Introduction
Not interested in background on K-means clustering? Skip to the questions here.
In preparing for your next Machine Learning Interview, one of the topics you certainly need to be familiar with is K-means. This algorithm is incredibly useful for clustering data points into groups that have not been explicitly labeled! The days of Machine Learning taking over the world are well within their stride, so it is important to have a solid grasp on concepts such as this one.
Check out my in-depth tutorial on implementing K-means from scratch in python if you are not familiar with the algorithm!
This series of articles is meant to equip you with the knowledge you need to ace your ML interview and secure a top tier job in the field. Once you decide you join in the hunt to master this craft, companies will come after you to get you!
Article Overview
- What is K-means clustering?
- How does K-means clustering work?
- Why is K-means clustering important?
- K-means ML Interview Questions and Answers
- Wrap Up
What is K-means clustering?
It is a very popular unsupervised clustering algorithm. It does not require labels to train the model, it only needs data.
Its main objective is to cluster data points that have similar properties into certain groups (k number of groups) to discover underlying structures and patterns of the dataset. The name k-means is given because it will cluster data into k groups which is given to the algorithm. In this algorithm, “k” is a hyperparameter and its optimal value needs to be figured out by trying different values of k.
How does K-means clustering work?

It calculates the centroid for each k cluster on dataset and tries to find the optimal centroid for every cluster in successive epochs. After learning optimal centroid values, these centroids are used to classify new data points into classes that have similar properties to it.
Why is K-means clustering important?
Clustering is a very important technique used to study data and make use of unlabeled data. It is also free from human bias as we are unable to capture every dependency for datasets containing millions of data points. In such scenarios, clustering comes handy. You may get confused in K means and K nearest neighbors due to the similarity in their names. K nearest neighbor algorithm is a supervised learning algorithm which is one of their biggest difference.
K-means ML Interview Questions and Answers
Some potential interview questions on K means clustering that you may encounter are shown below. Try to answer them in your head before clicking the arrow to reveal the answer.
K-means algorithm cluster similar data points using the centroid of each cluster. New data points are classified using these centroids, whichever cluster it fits in, it belongs to that class.
The goal of our K-means is to organize our data into K-distinct groups. If for instance, we chose k = 2, then what we want is for K-means to accomplish is to separate these data into 2 groups
- First step is to pick K random points (here, 2) and assign them to different labels. These points are called centroids
- Next we find the distance between centroid 1 and every other data point there is
- We repeat the previous process for centroid 2 as well. Whichever centroid is closest to a given point, that point will take on that centroid label.
- Then what we do is update the centroid to be the average of all the points in the given cluster
- We repeat steps 2-4 over and over again until centroid locations do not change after they have been updated. This means our K-means have converged.
K-means assumes all the clusters are continuous and the variables have symmetric distribution. It does not work well with skewed dataset. So, we must assume these variables should have similar mean and variance to use it.
K means follows unsupervised machine learning approach as it does not require labels along with data to train model.
Here in k means, k refers to the number of clusters in which all the data points will be grouped. K is a hyperparameter and is specific to every data set. The performance of the algorithm depends on the value of K. For the optimal value of k, it performs best and for remaining values. Its performance fluctuates between the best and the worst depending on the properties of dataset.
We use Dunn Index and Inertia to evaluate the performance of k means algorithm.
It is a simple approach and it converges to a local minimum. It works well with big datasets as well. Also, it can easily adapt to new examples. Additionally, it can cluster data points that are distributed in spherical clusters. Its results are easy to interpret.
Its biggest con is finding the optimal value of k. K’s value can only be examined manually and it can be done using the hit or trial method or searching values for k in a given range. It can be time-consuming.
Another issue is the curse of dimensionality, as number of dimensions increase, it becomes harder to cluster data. It can not classify overlapping data points efficiently. Very large dataset may cause trouble and it is also prone to outliers and noisy data.
Additionally, K-means can not accommodate clusters that are elliptical or other complex shapes. It struggles with datasets that have clusters of difference sizes since the cluster variance is completely ignored.
It is used in customer segmentation to cluster customers on basis of past records. It is used in banking, telecommunication, sales, advertisement etc. to cluster similar customers.
Additionally, It can be used to build recommendation systems which recommend personalized services and content to users.
K-means is also used for image segmentation tasks. It is also used to filter spam and for fraud detection. It is also used to build search engines and document clustering.
The Dunn Index is a clustering outcome measure. A greater value is preferable. It is calculated as the smallest intercluster distance (that is, the shortest distance between any two cluster centroids) divided by the greatest intracluster distance (i.e. the greatest possible distance between any two locations in any cluster)
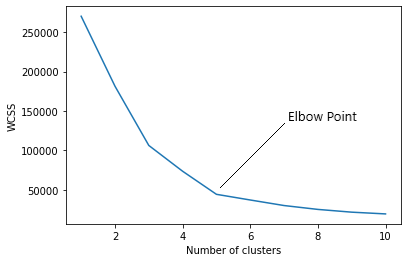
- Elbow method: This involves plotting the inertia against all of the different Ks that we can pick. As a rule of thumb, the best K is typically the number of clusters whose inertia differential to the next is low. You are on the lookout for where the curve becomes less steep. In the elbow plot below, the curve became less steep after cluster 5. Thus, the best value for K is 5.
- Silhouette Method: This takes into account the ratio of the inter and intra clusters distances. A silhouette curve can also be drawn just like the elbow curve. Just that this time, the curve is inverted and the best K is the point at which the curve becomes very steep.
- K-medians: here we use Manhattan distance instead of Euclidean distance
- K-modes: This variant is useful if we don’t have numerical data. It gauges distance on the dissimilarities of the examples and it uses the modes of the most recurring elements in those dissimilarities to organize these clusters.
If we use K-means, it would split the data from the middle. Whereas, normally, the outer circle should be one category and the inner circle to be another category. The algorithm to help solve this problem is Agglomerative Clustering.
The k-means++ algorithm addresses the second of these obstacles of bad approximation with respect to an objective function by specifying a procedure to initialize the cluster centers before proceeding with the standard k-means optimization iterations. It is primarily used for selecting the best initial value for k.
k-Nearest Neighbors is a classification (or regression) algorithm. The basic idea is to figure out what an unlabeled example is according to its neighbors. It is a supervised learning algorithm. On the other hand, k-Means is an unsupervised learning clustering approach that attempts to split a set of points into k groups so that the points in each cluster are close to each other.
So the major difference is the K-Means clustering is an unsupervised learning algorithm while K-nearest neighbor is a supervised machine learning algorithm.
- The Manhattan distance calculates the distance between two places by averaging the paired absolute differences between each variable.
- Euclidean distance captures the distance between two points by aggregating the squared difference in each variable.
Manhattan distance is typically used when you wish to calculate the distance between two points in grids. For instance, a city, where houses are in blocks. Euclidean distance however is used to measure the shortest distance between two points. For instance, the distance between two trees on a plain field.
Wrap Up
K-means is a very useful unsupervised approach in Machine Learning. It is widely used in industry to get meaningful insights from Big Data. As organizations have data of millions of users, using unsupervised algorithms like K-means, they cluster their customers in various groups to provide better services to customers and use the Big Data efficiently.




