

Other Topics — Machine Learning Interview Questions
Introduction
Not interested in background on DBSCAN? Skip to the questions here.
Evolution continues day by day in the field of Machine Learning. Newer concepts continue to come to the forefront. Therefore, it is imperative that ML Engineers stay in touch with these new entries as well as past ones in order to not only excel in their field but also get a chance to do so as well. Henceforth, let us have a look at once such evolution in DBSCAN.
Article Overview
What is DBSCAN?
It is an unsupervised ML algorithm that stands for ‘Density-Based Spatial Clustering Application with Noise.’ It is yet another clustering algorithm, and it creates clusters depending on the density of the data points (as in how close the data points are to one another.)
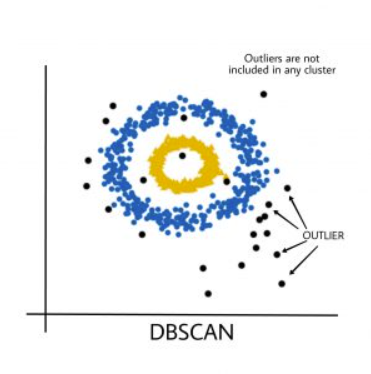
How does DBSCAN Work?
DBSCAN works by utilizing the following steps:
1) The user selects the values of its parameters eps and min_pts.
2) For every point ‘x’ in the dataset, its distance is computed with respect to every other data point.
3) If the above distance is either less than or equal to eps, then that point becomes the neighbor of x.
4) If x has the count of its neighbor greater than or equal to min_pts, then it becomes a core or visited point.
5) Then, for every core point, if it does not already belong to any cluster, a new cluster is created.
6) Now, all the neighboring points are determined recursively and then allotted to the exact cluster as the core point.
7) The above steps are repeated till every point has been looked at or traversed over.
DBSCAN ML Interview Questions/Answers
We can see that the DBSCAN algorithm has its similarities to other clustering algorithms. Therefore, we must find out why it is preferred over the others in certain situations and what it is all about. Therefore, let us have a look at a few questions related to it. Try to answer them in your head before clicking the arrow to reveal the answer.
There are two parameters employed in it:
- eps: This is known as epsilon and dictates what points are considered neighbors as it is the maximum distance between two points that can be considered as such. To keep it simple, eps can be seen as the radius around each point.
- min_pts: This is known as minimum points or minimum samples and is basically the number of observations that have to be around a point within a radius so that that point is considered a core data point.
In such cases, eps can be understood as the radius of a hypersphere, whilst min_pts can be understood as the minimum number of data points needed inside that hypersphere
Direct Density Reachable: stands for a point that has a core point in its neighborhood.
Density Reachable: a point is density reachable from the other if both end up being connected through a series of core points.
Density Connected: two points are density connected if there is a core point that is density reachable from both points.
Three points are gotten:
1) Noise Point: which is neither a core point nor a border point. Rather, it is considered either an outlier or noise.
2) Core Point: which is any point that ends up having min_pts at an eps distance from it.
3) Border Point: which is any point that has at least one core point in its neighborhood but less than min_pts.
Its effect is evident, and the algorithm is quite sensitive to it as well. In the scenario where there is a presence of clusters with different densities involved, two situations may occur:
1) Epsilon being too small: where the sparser clusters are considered noise, and this results in their elimination as outliers.
2) Epsilon being too large: where the denser clusters are merged with one another, and this results in incorrect clusters.
The most widely utilized algorithm in this domain is, as expected, DBSCAN itself. Its incorporation of density reachability and density connectivity, coupled with even discovering outliers or noisy points, is commendable. This specific quality makes it ideal for clustering and outlier detection with any shape.
Some advantages of DBSCAN are:
1) Unlike K means, in DBSCAN, the user does not give the number of clusters to be generated as input to the algorithm.
2) Clusters can be of any random shape and size, including non-spherical ones.
3) It can identify noise data, popularly known as outliers.
4) It does not need a predefined number of clusters
5) Density-based clustering algorithms don’t include the outliers in any of the clusters. Outliers are considered noise while clustering, and hence they are eliminated from the cluster after algorithm completion.
Some disadvantages of DBSCAN are:
1) It is sensitive to parameters, i.e., it’s hard to determine the correct set of parameters.
2) It becomes challenging to detect outlier or noisy points if there is a variation in the density of the clusters.
3) DBSCAN clustering fails when there are no density drops between clusters.
4) With high dimensional data, DBSCAN does not give effective clusters
5) Not partition-able for multiprocessor systems.
6) It is pretty slow.
Wrap Up
We see from the above that there is a definite application for DBSCAN in the world of Machine Learning. In fact, it poses significant advantages in some cases over its counterparts like k-means clustering. Its ability to identify outliers is one that is exceptionally vital. However, it being slow can end up hindering its use.




