

Not interested in background information? Click here to go to the code!
Generative adversarial networks, commonly referred to as GAN’s, have shown quite incredible performance at image generation tasks. GAN’s generally take in a latent vector and output some image that represents a mapping to some point in latent space. However, the intermediate latent space that a GAN learns has the potential to be utilized to disentangle this abstract process into something more easily understood by humans.
Various attempts have been made to establish an interface for humans to synthesize and edit images, however most have not been sufficiently intuitive or flexible. Interfaces for editing images in the latent space of a network often end up with an overwhelming amount of niche sliders that make minimal difference unless utilized together. While it is still valuable to disentangle our representation and say that adjusting weights 1-3, for example, will change hair color, hair style, and hair density, this is not very practically useful. Additionally, when trying to add a new disentanglement, it requires additional data processing and evaluation to determine which weights affect the new target semantic direction.
This is where StyleCLIP comes in and shakes up a lot about what we know about using a GAN to modify real and synthetic images. StyleCLIP combines StyleGAN along with CLIP to allow us to generate or modify images using simple text based inputs. The paper introduces three methods of combining CLIP with StyleGAN for image synthesis, all of which will be discussed in detail.
Article Overview
- What is StyleGAN?
- What is CLIP?
- Text-guided latent optimization
- Latent residual mapper
- Mapping a text prompt into an global direction in StyleSpace
- Creating your own images
- What is the difference between the W and W+ Latent Space in StyleGAN?
What is StyleGAN?
Created by NVIDIA, StyleGAN adds to the body of work around progressive growing GANs, which are trained initially at low resolutions and scaled up to produce compelling high resolution images. StyleGAN differs most significantly in the structure of its generator function. Instead of taking in a single input latent vector, StyleGAN has a more complex weight mapping. The output of the mapping function, w, is broken into its component weights which are fed into the model at different points. Additionally, StyleGAN utilizes noise layers to introduce Stochastic variation into the model. A different noise vector is passed into each block of the model prior to the adaptive instance normalization (AdaIN) layer. Learn more details about the architecture of StyleGAN here.

What is CLIP?
Contrastive Language-Image Pre-training or CLIP is a model for generating natural textual representations of images. CLIP works by creating an embedding space with both an image and text encoder working on a very large dataset. In the embedding space, cosine similarity can be used to compare an image and a description. The more semantically similar, the higher the cosine similarity between text features and the image will be.
StyleCLIP utilizes CLIP as a loss function to give the generative adversarial network feedback.
Text-Guided Latent Optimization
Latent code optimization is the simplest way to utilize CLIP to guide the synthesis of images. First, a starting weight w is passed into our generator function. After, the output of the generator is compared to the target text in the CLIP embedding space. The cosine distance is used to inform the update step. The initial weight w is updated and the cycle continues. In the paper, the researchers stated they used 200-300 iterations using this method. The optimization function is shown below.
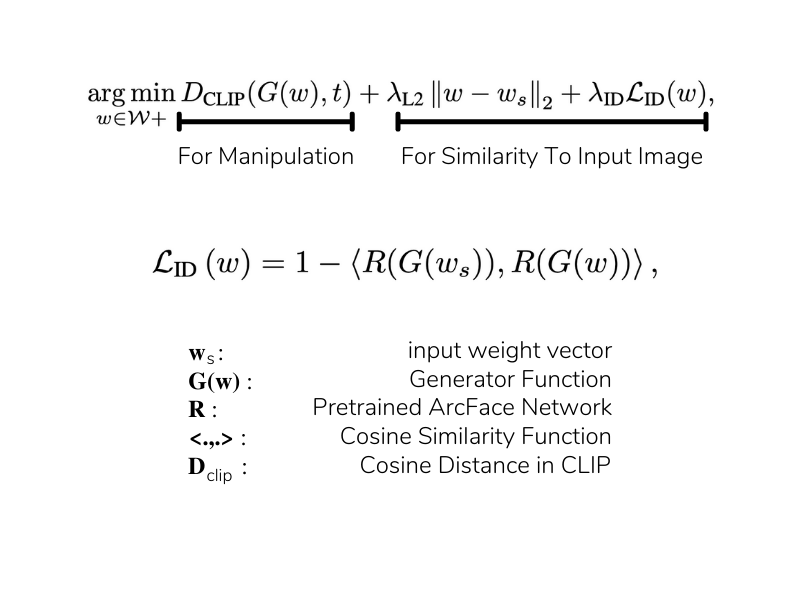
Latent Residual Mapper
The latent residual mapper is similar to the mapping function f defined in StyleGAN, however in this case there are three fully connected networks, one for coarse, medium and fine grain details. Each FC network has the same architecture as the StyleGAN mapper network but with only 4 layers instead of 8.

This mapper based approach allows for a transformation, such as the “surprised transform” to be applied to any input image. However, the mapper is generally only trained on one or a handful of specific features. So, you would likely need to train multiple mappers for each type of transform you want to do.
Global Direction in StyleSpace
Analysis of the similarity between manipulation directions obtained from mappers over a set of images revealed that there was no that much difference in the instruction/weight update occurring from one image to another. To put it simply, each mapper would give similar manipulations regardless of the input, suggesting the global direction is possible.
The authors chose to operate in the StyleSpace S, as this is known to be more disentangled than other latent spaces. Taking in a text prompt, we seek the generalized manipulation direction ∆s, such
that G(s + α∆s) produces the target.
G represents our generator function, s represents the input image, and α is the magnitude of manipulation.
The method for global direction is illustrated by the image below.

Creating Your Own Images with StyleCLIP
If you do not have access to a computer with an NVIDIA graphics card, you will be unable to run the code on your local machine. In this case you must use a cloud service like Google Collab which offers CUDA support.
I do not have a NVIDIA graphic card so we will look at generating images from the global mapper jupyter notebook, which can be found here.
Run Setup
To get started making your own synthetic images, start be opening the notebook and running the setup cell. You can run all the cells as is up until the one labelled Align Image.
Uploading Your Image

Once you get to the Align Image cell, you can upload your own image. There are a couple specifications for the image.
- Image should be 1024 x 1024
- Image must be related to the selected dataset. Currently only ffhq is supported in the notebook which means the image you select has to be a person’s face, cropped from about shoulder up.
- If your image is not related to the dataset, StyleCLIP will not be able to find a parity in the StyleSpace to do manipulations on.


Now you can change the path in the Align Image cell to be the image you just uploaded. Once you run the Align Image cell, you will see one of two things.
Successful Alignment will look like this:

Unsuccessful alignment will look like this:

After successful alignment, generate the inverted image in the next cell. Afterwords, we can ignore the Choose Image Index cell. Run the Choose Mode cell after selecting real image.

(Right): Closest synthetic match to input picture in StyleSpace
Modify the input image with text prompts
We can now use the power of StyleCLIP to generate images based off our input image. We have to first define the ground label for our image. I described my picture of Neil Patrick Harris as “male face with short blonde hair”. In my experience messing around, being more descriptive for the neutral statement seems to have better results. We can slightly modify the neutral statement to produce our target statement and then run the input text description and modify manipulation strength cells in the notebook.

Adjusting Manipulation Parameters
The parameter β represents a threshold above which a given weight will be considered relevant for the image transformation at hand. As we discussed, there are many channels in the weight vector w, which is output from the mapping function, f. The β threshold determines which of these channels will be perturbed to achieve the target.
The α parameter represents the magnitude of the manipulation. A positive alpha value indicates movement in the direction of the target value while a negative alpha will produce the opposite results of the target.
Play around with these parameters because they actually have a significant impact on the output quality. Also consider the merits of this system over an approach that utilizes upwards of 50 sliders of niche purpose.

So, we’ve learned how to use StyleCLIP to modify an input image with text based instructions. I had a ton of fun playing around with this code so enjoy a gallery of the many faces of Neil Patrick Harris.

“angry male face with short blonde hair” “female face with short blonde hair” “asian female face with short blonde hair” “asian male with short blonde hair” “male face with short blonde hair and earrings” “ginger male face with short blonde hair”






What difference between W and W+ space StyleGAN?
W represents a disentangled latent space of StyleGAN. The W space is comprised of 512-dimensional vectors w ∈ W. The W+ space is simply an expanded version of the W space. So, the W+ space is comprised of concatenations of 18 different 512-dimensional w vectors, one for each layer of the StyleGAN architecture that can receive input via AdaIn.



")
